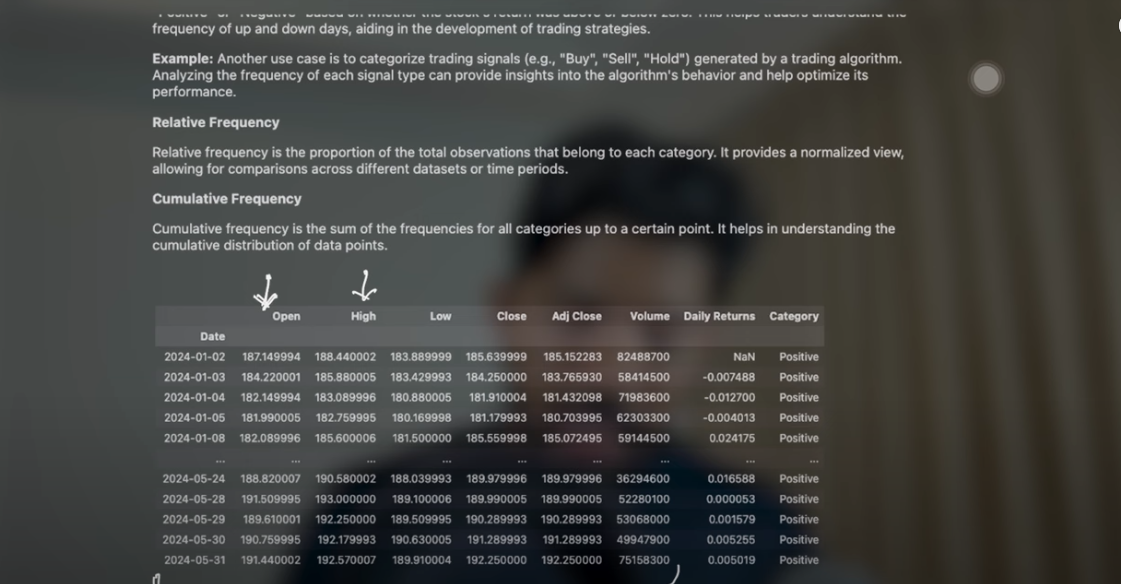
Role of Data Cleaning and Descriptive Statistics in Algo Trading
Data cleaning is a crucial step in algorithmic trading, which ensures that stock market data sets are accurate and reliable. The cleaned data is analyzed through descriptive statistics, which helps in making better trading decisions.
Why is data cleaning necessary in algorithmic trading?
Before applying descriptive statistics on financial data, data cleaning is necessary. The following problems can arise due to poor data quality:
Inconsistent trading signals leading to wrong investment decisions.
Higher risk due to incomplete or missing data.
Incorrect trend analysis, thereby affecting the prediction of stock prices.
To avoid these problems, traders clean and pre-process their data using Python.
Process of Data Cleaning
Managing missing values: Removing missing data or filling it with suitable values.
Data standardization: Transforming data into a uniform format to ensure consistency.
Identifying and managing outliers: Detecting and handling abnormal values in data.
Application of Descriptive Statistics
By applying descriptive statistics on the cleaned data, traders can understand the central tendency (e.g., mean, median, mode) and spread (e.g., range, variance, standard deviation) of the data. This understanding is helpful in developing algorithmic trading strategies.
Using Python in Algorithmic Trading
Python’s extensive libraries, such as Pandas and NumPy, simplify data cleaning and analysis. Using these tools, quantitative traders can develop stock market algorithms and implement crypto trading strategies.